
机器学习记录
不同的维度,看到的事物的形态也是不同的. 横看成岭侧成峰,远近高低各不同.
最简单的公式
$$
f(x)=XW+b
$$
有一堆数据,能够知道 x 和 y .现在我们通过一些方法来求出 W 和 b ,这样当有未知的 $X_n$ 通过 W 和 b 就能够求出 $f(x_n)$ 的值.
当把维度增加,公式就变成了
$$
f(x_1..xn)=X_1W_1+…X_nW_n+b
$$
https://microsoft.github.io/ai-edu/基础教程/
反向传播:
https://www.jiqizhixin.com/graph/technologies/7332347c-8073-4783-bfc1-1698a6257db3
https://zhuanlan.zhihu.com/p/40761721
正向传播: 传播信号从输入层到隐藏层到输出层,一层一层的传播,最后得到结果.
反向传播: 输出结果和真实结果存在误差,通过误差反向的传递给前面的个层,来调整网络的参数.
$$
f(x) = ax_1+bx_2
$$
如果 f(x) = z 而我们计算的值为y 那么误差为 m=z-y,那么我们需要通过误差来调整参数 a 、b 的值. 当误差值不断往前传播,最后通过误差计算出新的权重的过程.
https://cloud.tencent.com/developer/article/1897045
CNN: 卷积神经网络
http://arthurchiao.art/blog/cnn-intuitive-explanation-zh/
卷积的四种操作
- 卷积 : 通过小矩阵对输入矩阵进行运算,学习图像特征,通过 ilter 保留像素空间关系.
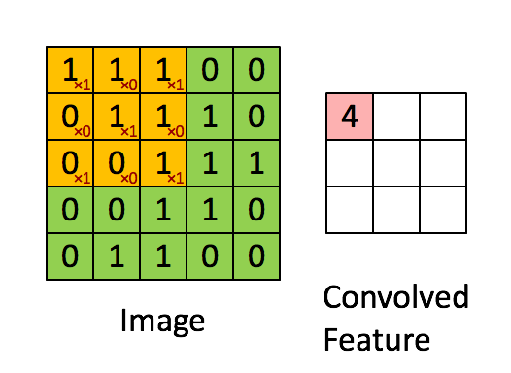
- 非线性:卷积后通过一个称为 ReLU 的运算
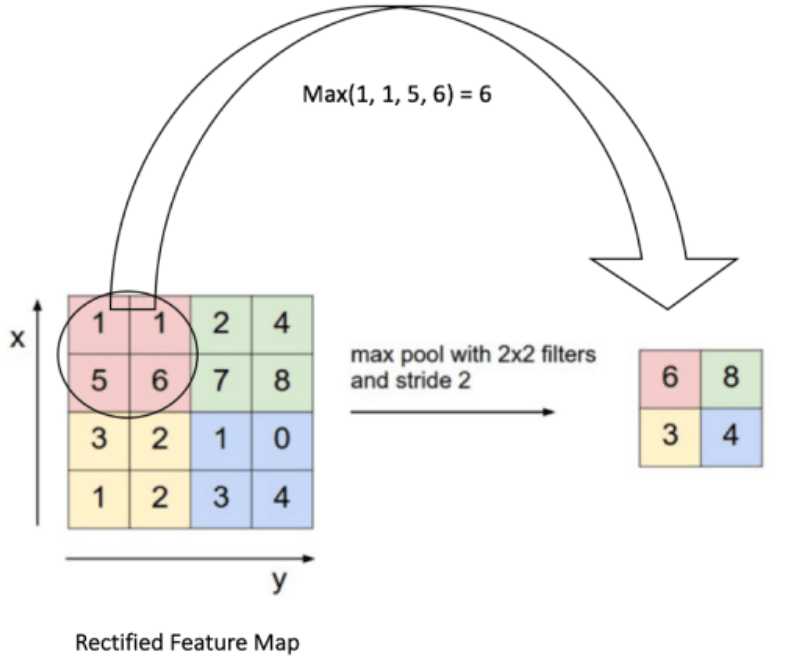
- 池化或降采样: 对卷积+ ReLU 的特征做降采样,比如44 降为22
分类/全连接
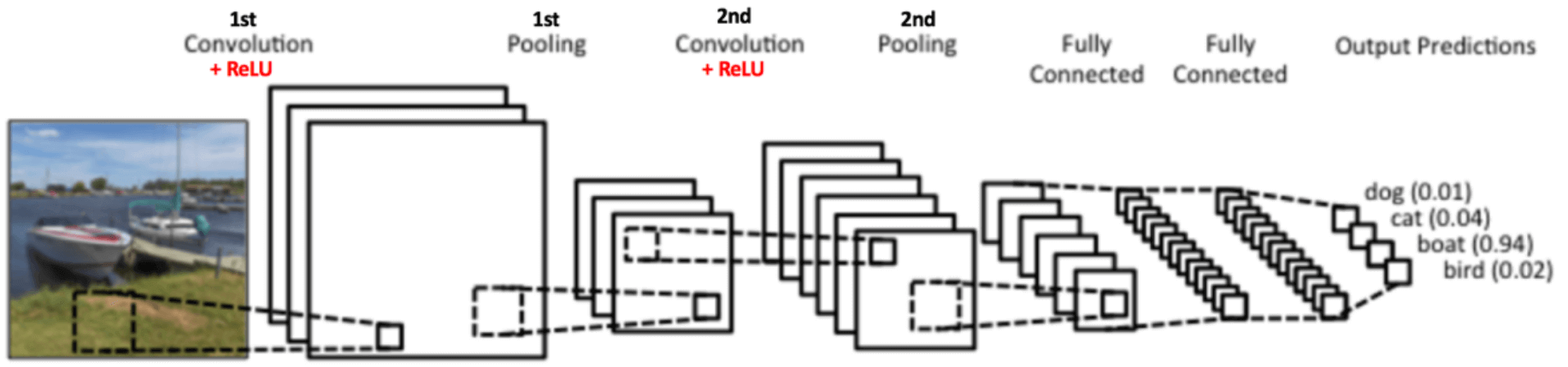
比如上图做两次卷积后,在做全连接.
卷积+降采样作为特征提取,全连接作为分类器
RNN 循环神经网络
http://fancyerii.github.io/books/rnn-intro/
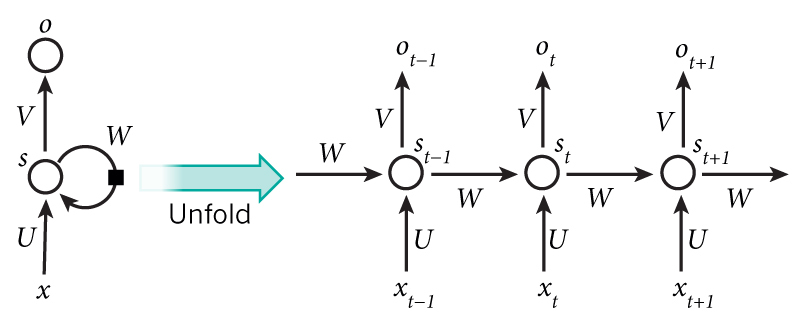
$x_t$ 为 t 时刻的输入
$s_t$ 为 t 时刻的隐状态,它可以看作是网络的记忆
$s_t = f(Ux_t+Ws_{t-1})$
使用上一层的输出和当前的输入作为当前的输入.
上一层的输入是前面权重计算,层数越多,前面层的影响越小(权重会越来越小),存在短期记忆的问题.
另外的
- 双向 RNN
- 深度双向 RNN
- LSTM
- GRU
transformer
https://cloud.tencent.com/developer/article/1897045
Transformer的优势在于,它可以不受梯度消失的影响,能够保留任意长的长期记忆。而RNN的记忆窗口很短;LSTM和GRU虽然解决了一部分梯度消失的问题,但是它们的记忆窗口也是有限的。
encoder-decoder 结构
https://luweikxy.gitbook.io/machine-learning-notes/seq2seq-and-attention-mechanism
给定的输入 encoder 后计算得到中间语义,使用 decoder 解码.
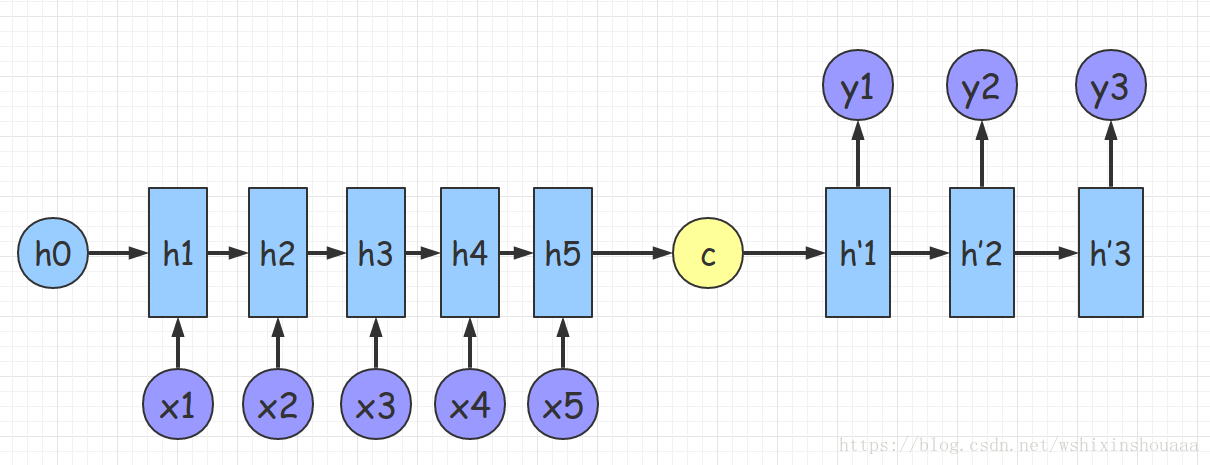
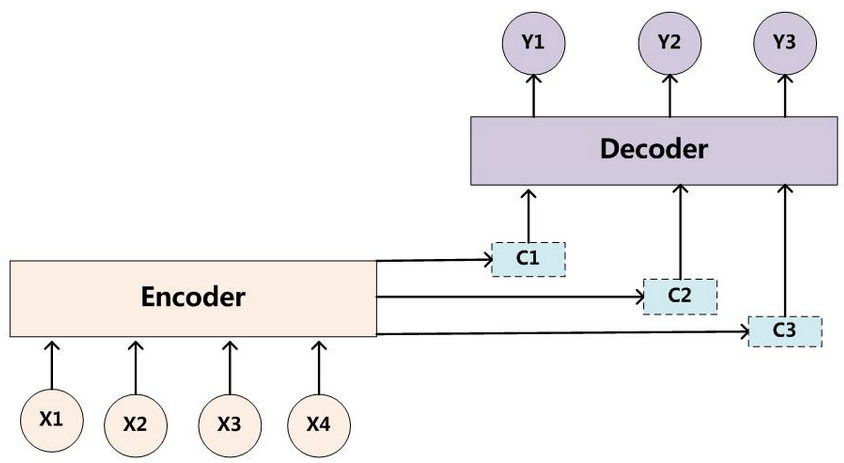
attention 注意力机制
不在将输入编码成固定长度 .而是根据当前生成的新单词计算新的$C_i$
transformer结构
https://www.tensorflow.org/tutorials/text/transformer?hl=zh-cn
https://erickun.com/2020/04/11/Transformer-原理-源码分析总结-Tensorflow官方源码/
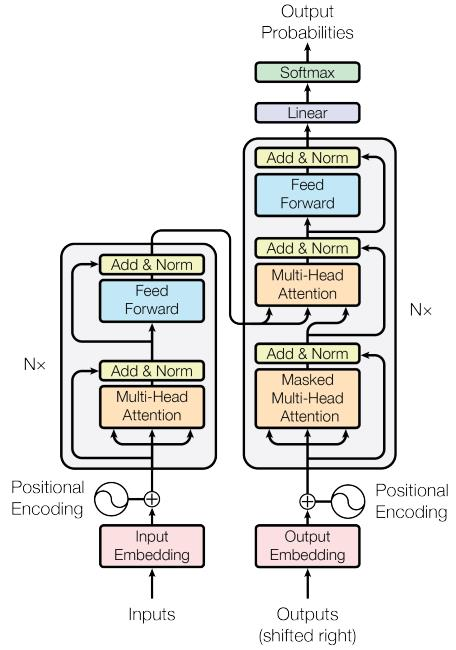
Transformer 结构分为编码器和解码器两部分. 编码器有 N 个层,解码器也有 N 个层.
Encoding
Positional Encoding
https://www.cnblogs.com/emanlee/p/17137698.html
transformer 是将所有词一起输入,并行操作,所以需要提供位置信息.
位置嵌入的维度为[max sequence length ,embedding dimension] (输入的最大单句长度 、 词的维度)
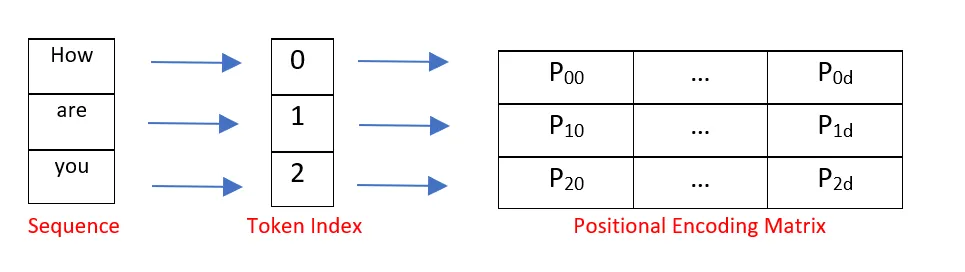
在论文中使用了 sin 和cos 函数的线性变换提供了模型的位置信息
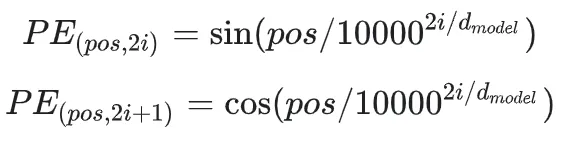
d:输出嵌入空间的维度
pos:输入序列中的单词位置,0≤pos≤L-1
这个公式的意义是,对于每个位置 pos 和每个维度 ,计算出对应的角度速率(angle_rate),用于位置编码中的计算。这样可以保证不同位置和不同维度的编码具有不同的特征,有助于模型更好地学习序列的位置关系。
1
2
3
4
5
6
7
8
9
10
11
12def get_angles(pos,i,d_model,n):
# pos/10000^(2*i/d_model)
denominator = np.power(n, 2*(i/d_model))
return pos/denominator
def getPositionEncoding(seq_len,dim,n = 10000):
PE = np.zeros((seq_len, dim))
for pos in range(seq_len):
for i in range(int(dim/2)):
PE[pos,2*i] = np.sin(get_angles(pos,i,dim,n))
PE[pos,2*i+1] = np.cos(get_angles(pos,i,dim,n))
return PE疑问:
使用 sin cos 交替的意义,奇数位和偶数位的位置描述不同? 如果直接使用随机数可行吗?
2*i/d_model 在值域上的变化为 0-1-2,中值为1 ,对应的指数函数的变化不同,表
示前半段的位置信息和后半段的位置信息不同?
在小说降临里面,对语言的描述是立体的,电影里面是一个环,而信息在环上延伸.最后学会了七支桶的语言,从而能够预测未来. 环描述了位置,也描述了信息.位置信息可能是相对的.
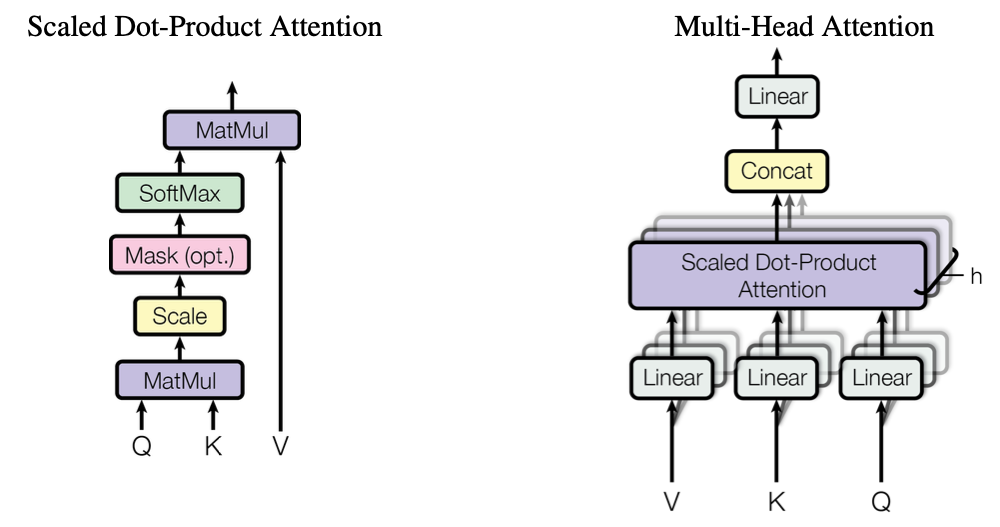
Multi- HeadAttention
https://imzhanghao.com/2021/09/15/self-attention-multi-head-attention/
https://www.cvmart.net/community/detail/5563
https://mp.weixin.qq.com/s/cJqhESxTMy5cfj0EXh9s4w
https://zhuanlan.zhihu.com/p/338817680
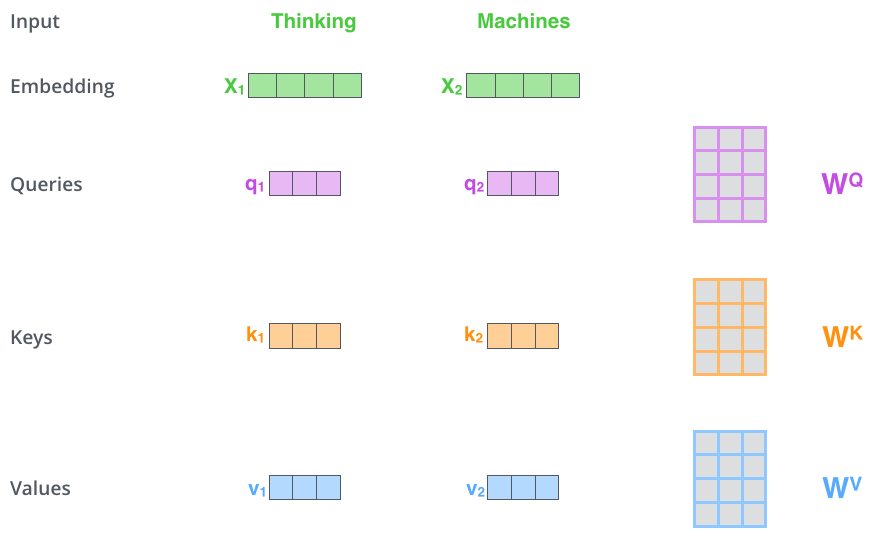
self Attention 自注意力机制
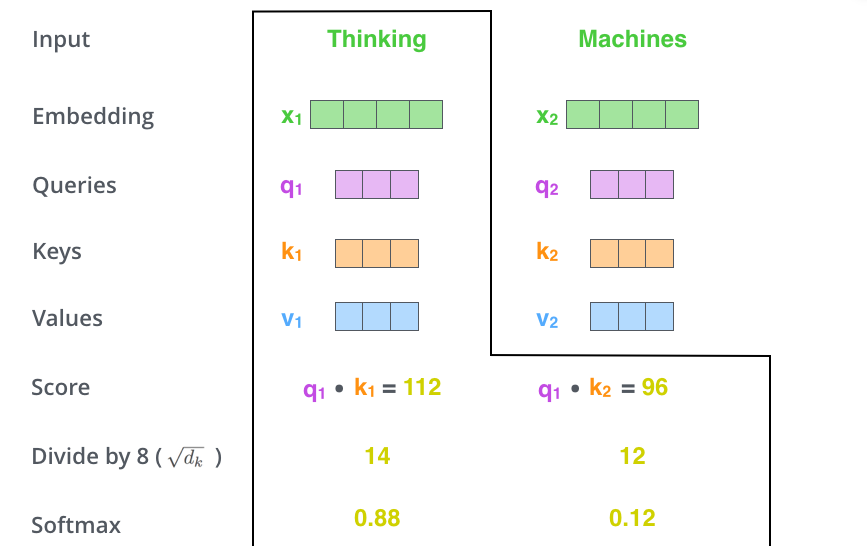
1.初始化Q,K,V
首先初始化三个权重矩阵$ W_Q 、 W_K、 W_V$ 然后将 X_embedding 与这三个权重矩阵相乘,得到 Q、K、V
- 计算 Self-Attention Score
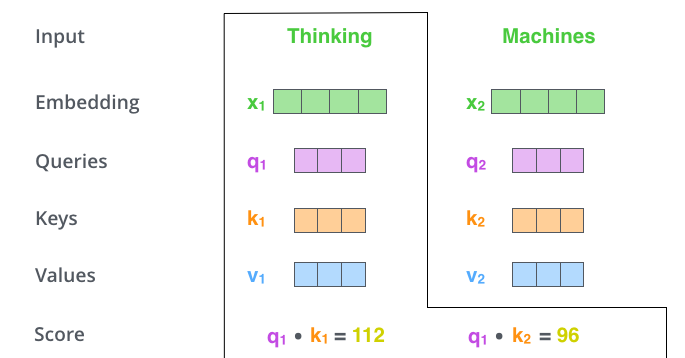
- 对Self-Attention Socre进行缩放和归一化,得到Softmax Socre
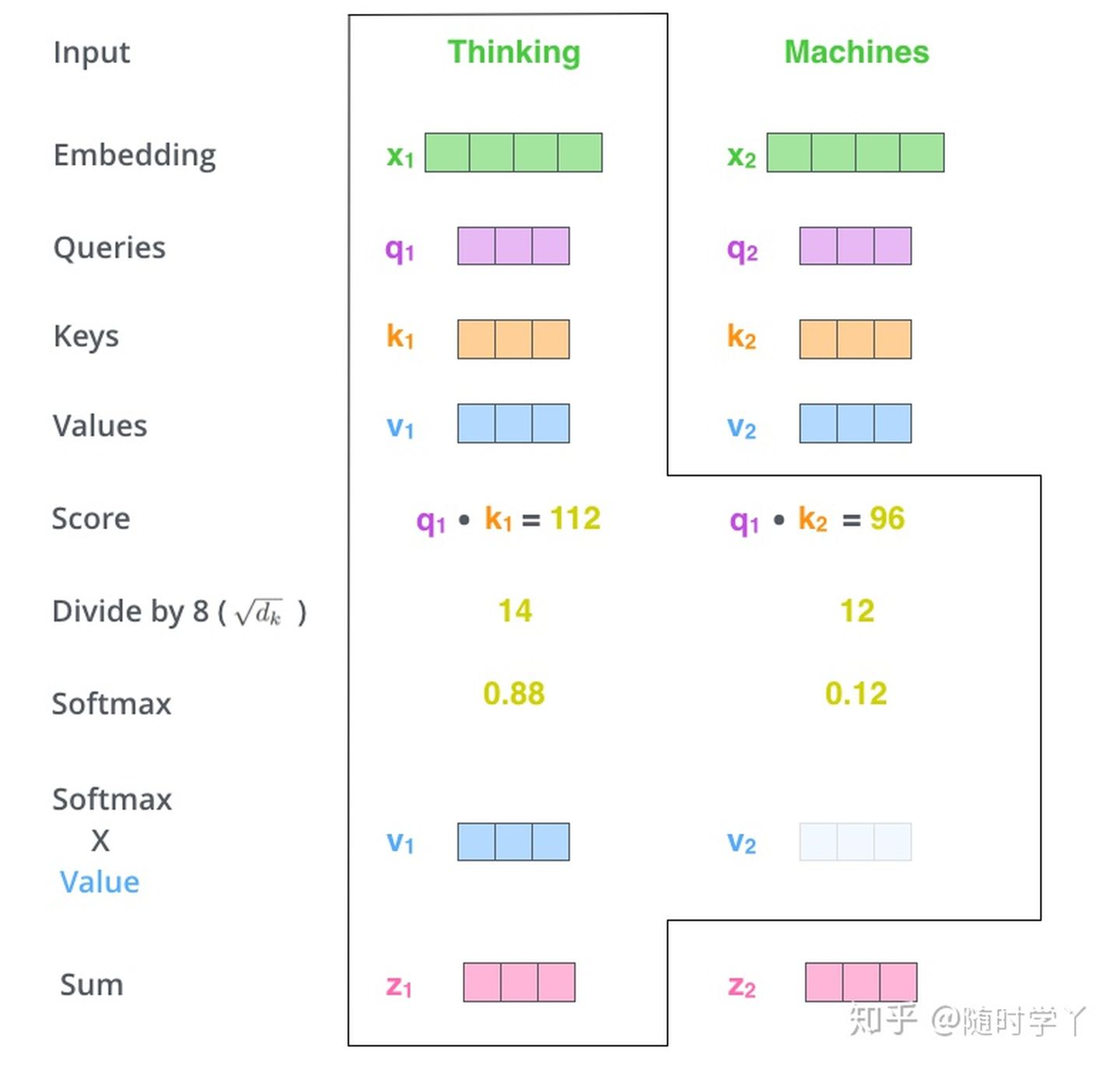
- Softmax Socre乘以Value向量,求和得到Attention Value
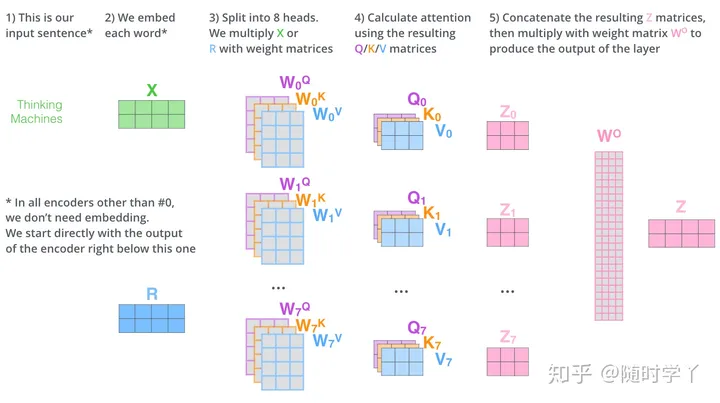
Multi-Head Attention的作用
将 Scaled Dot-Product Attention 的过程做 H 次(H=8)
把输出合并起来
$$
head_i = Attention(Q_i,K_i,V_i),i=1…8 \ MultiHead(Q,K,V) = Concact(head_1,…head_8)W^o
$$
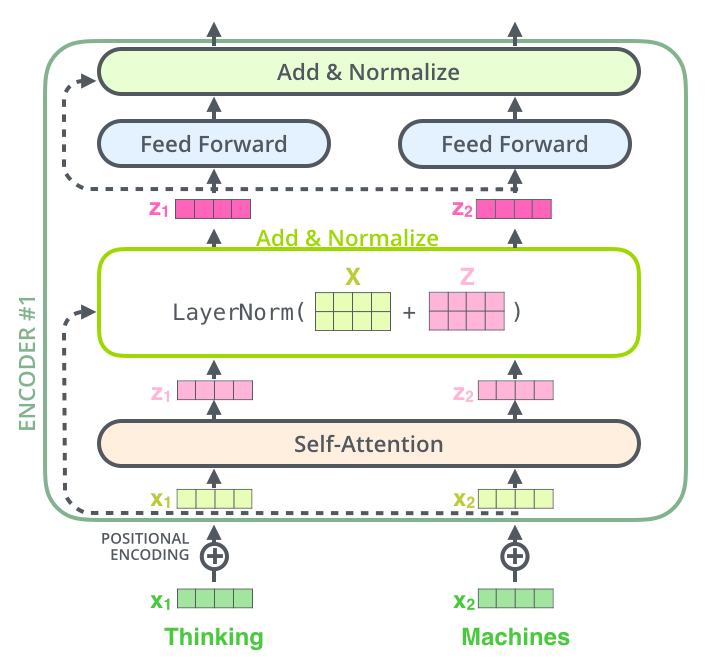
Add&Norm
Add & Norm 由 Add 和 Norm 两个部分组成
$$
LayerNorm(X+MultiHeadAttention(X)) \
LayerNorm(X+FeedForward(X))
$$X 表示 MultiHeadAttention 或 FeedForward 的输入
ADD 指的是 X + MultiHeadAttention(X) ,是一种残差链接,让网络指关注当前差异的部分.

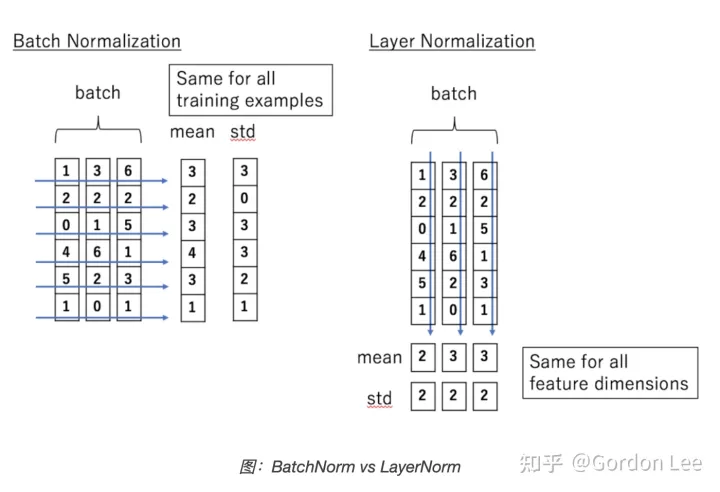
LayerNorm
https://zhuanlan.zhihu.com/p/492803886
对维度进行均值方差计算,LN 对 hidden 的维度做归一化操作.
Feed Forward
Feed Forward 是两个全连接层 ,第一层激活函数为 Relu ,第二层不使用激活函数
$$
max(0,XW_1+b_1)W_2+b_2
$$X 是输入,Feed Forward 最终的到输出矩阵的维度与 X 一致.
encode
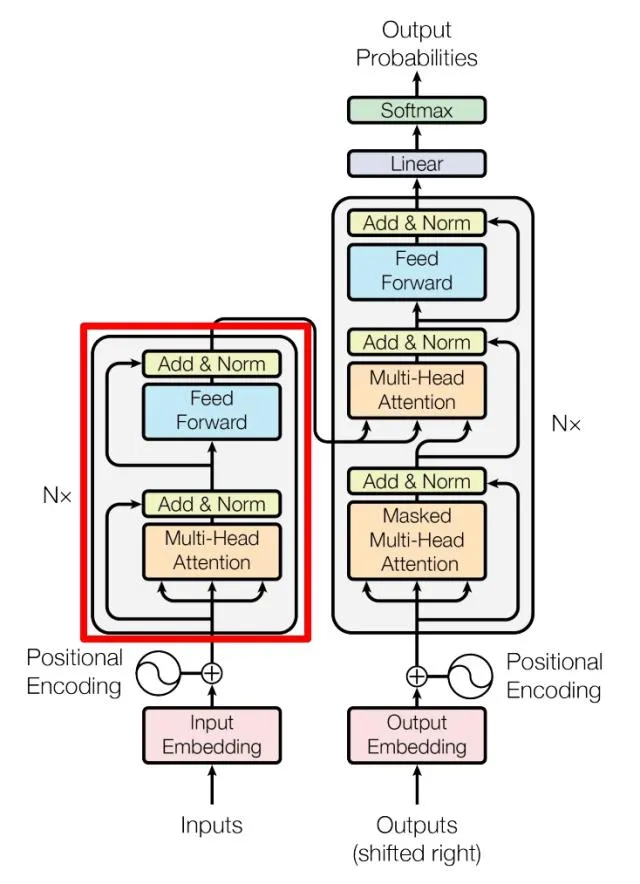
encode 的部分由 Multi-Head Attention , Add & Norm, Feed Forward, Add & Norm
decode
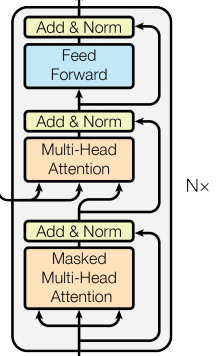
解码器由三层结构组成
第一层由带掩码(masked)的多头注意力层和一个残差连接
Masked 操作目的是将后面的内容做掩盖,因为在生成过程中,生成了第i个字,才能生成第 i+1 个. 通过 masked 可以防止第i个字知道i+1的内容.
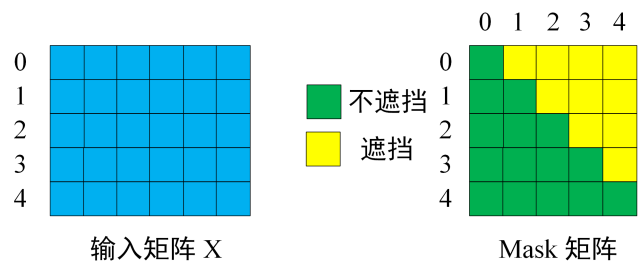
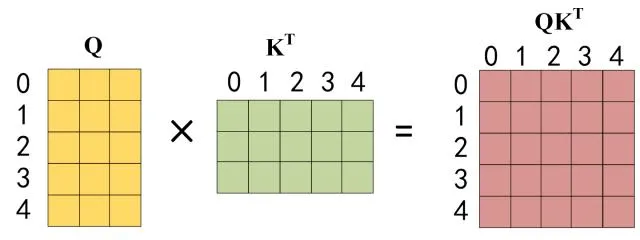

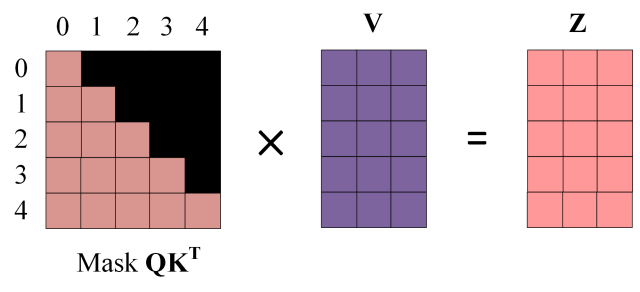
通过 masked 后的输出内容只有前 i 个字符的信息.
- 第二层也是一个多头注意力层和一个残差连接
根据 Encoder 的输出 C 计算得到 K,V ,根据上一次输出的 Z 计算出 Q.进行多头注意力计算和残差连接. (通过掩码的 Q 去 Encode 的 K V 里查询出可能的内容. )
- 第三层是前溃全连接层和一个残差连接.
计算方式与 encode 中的一致
最后线性层和 Softmax层
最后通过 Softmax 预测所有的单词
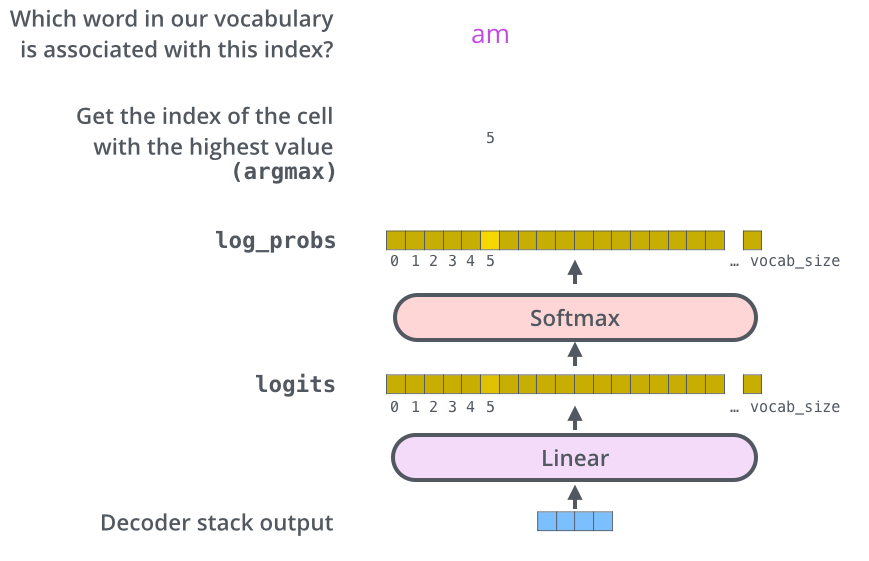
链接
google develop 的llm简介: https://developers.google.com/machine-learning/resources/intro-llms?hl=zh-cn
