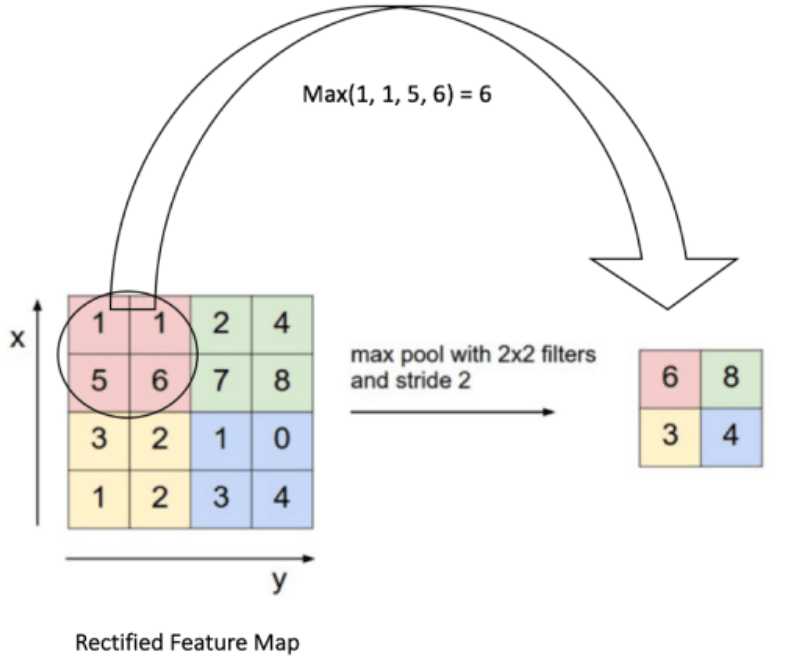
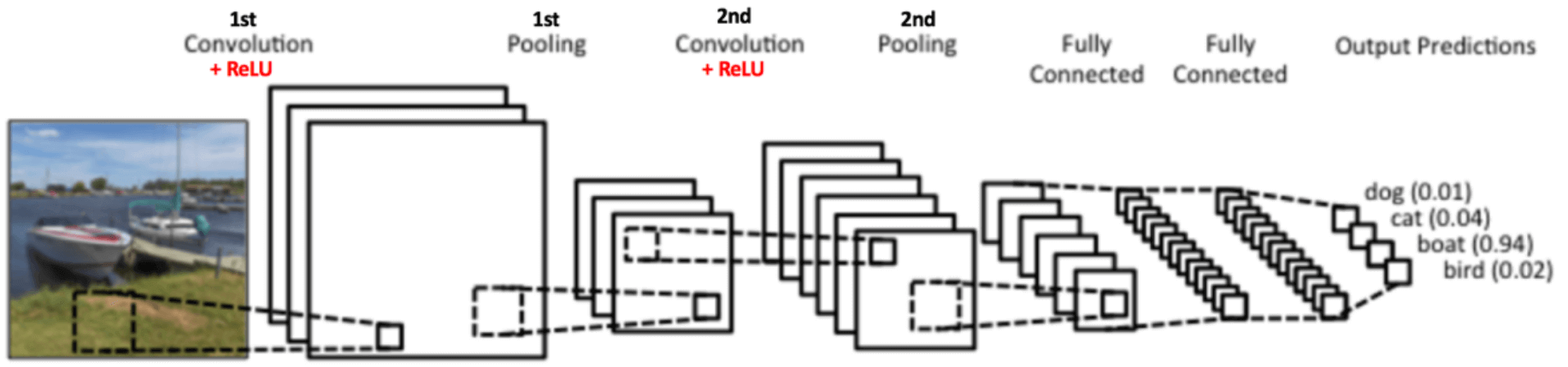
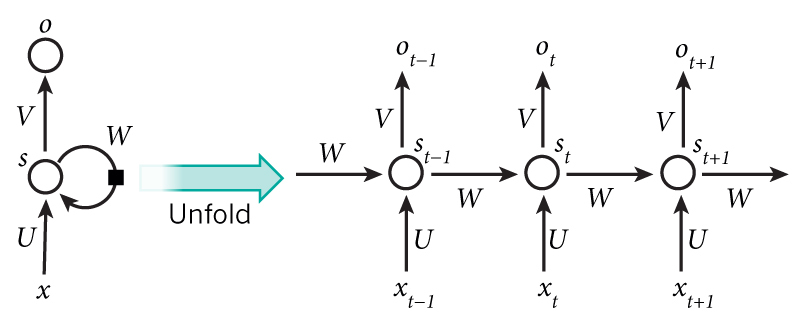
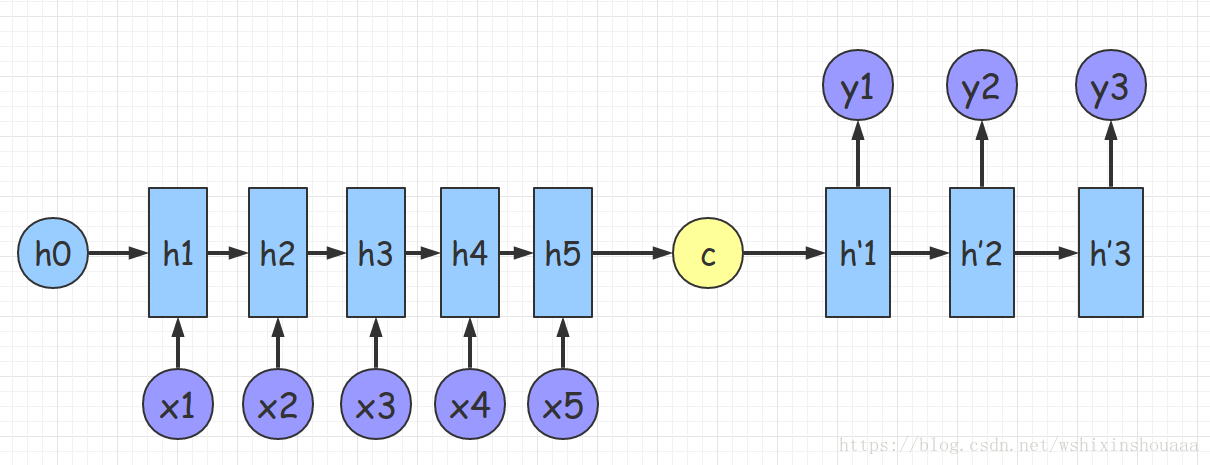
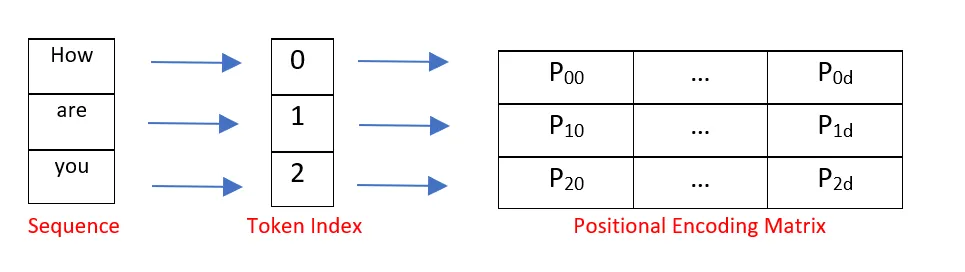
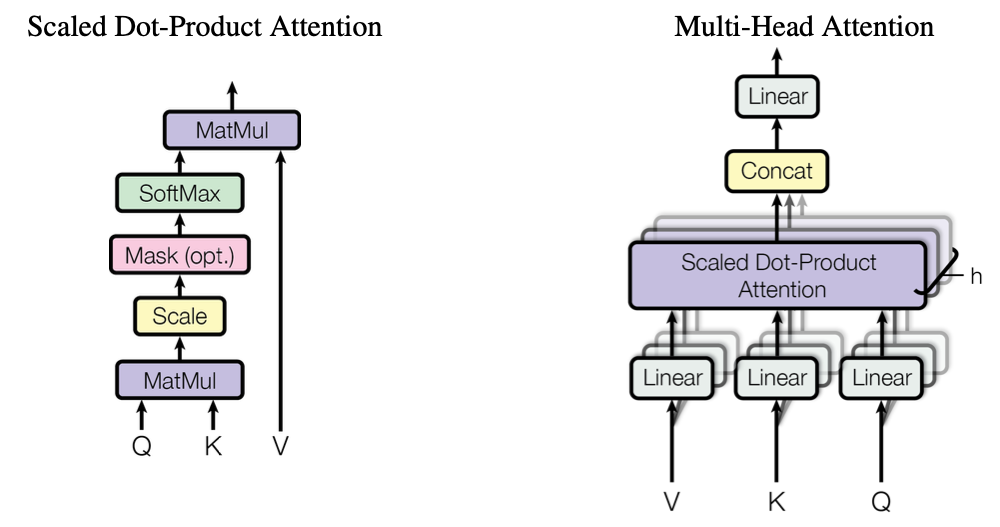
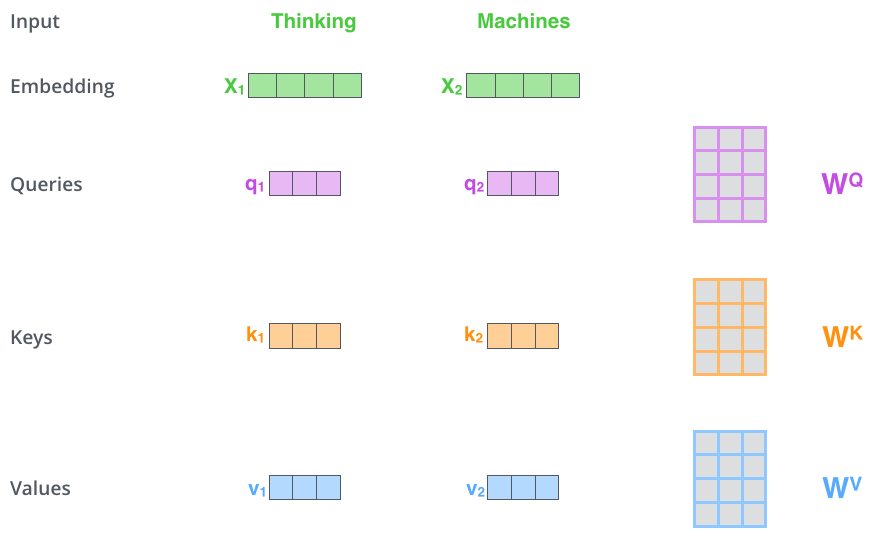
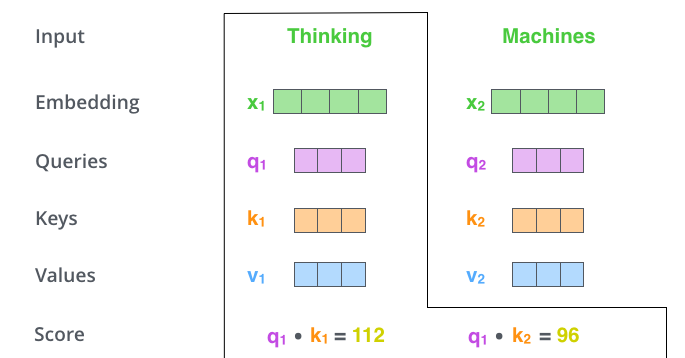
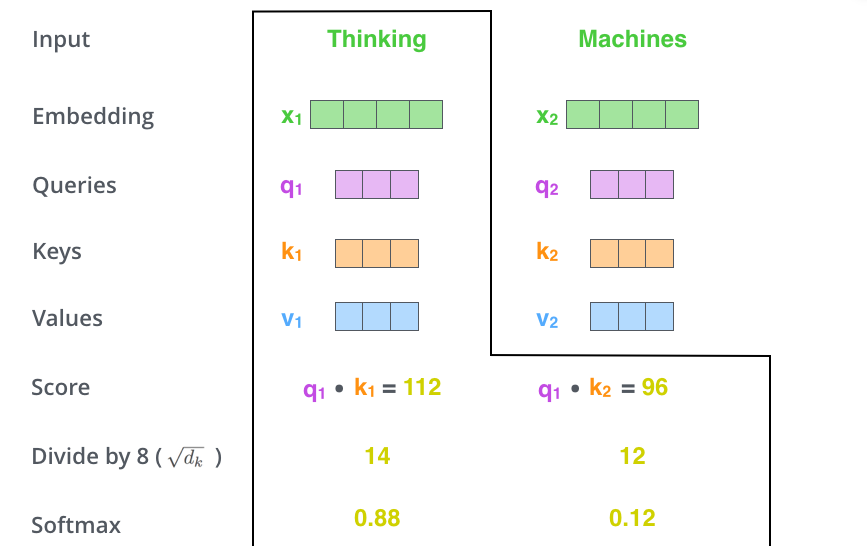
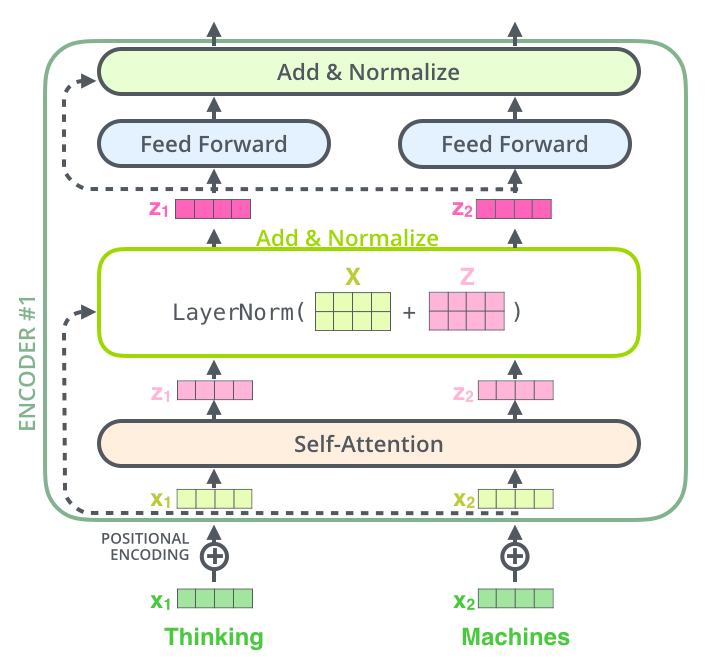
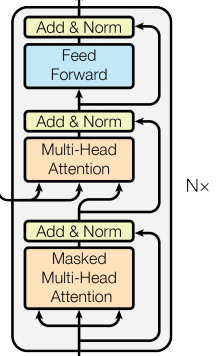
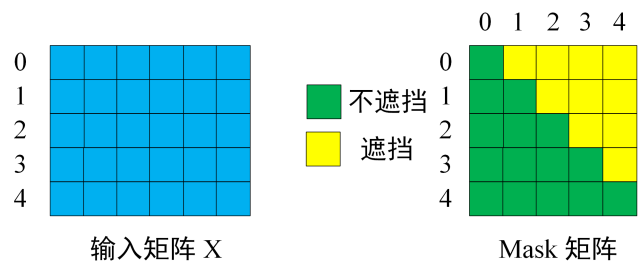
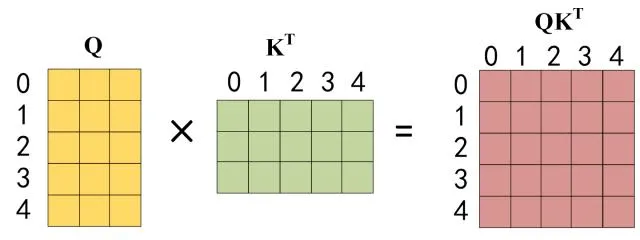
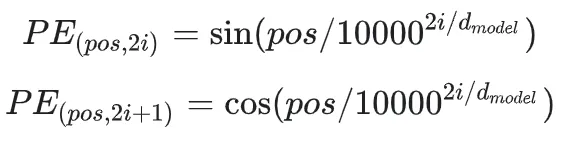def getPositionEncoding(seq_len,dim,n = 10000): PE = np.zeros((seq_len, dim)) for pos in range(seq_len): for i in range(int(dim/2)): PE[pos,2*i] = np.sin(get_angles(pos,i,dim,n)) PE[pos,2*i+1] = np.cos(get_angles(pos,i,dim,n)) return PE
| let mut dp_max = vec![0;nums.length()]; | ^^^^^^ help: there is a method with a similar name: `len`
未定义的结构体
1 2
34 | impl Solution { | ^^^^^^^^ not found in this scope
最后的返回没有分号
1 2 3 4 5 6 7
pub fn max_absolute_sum(nums: Vec<i32>) -> i32 { | ---------------- ^^^ expected `i32`, found `()` | | | implicitly returns `()` as its body has no tail or `return` expression ... 87 | res; | - help: remove this semicolon to return this value
计算最大绝对值函数的所有权
1 2 3 4 5 6 7
pub fn max_absolute_sum(nums: Vec<i32>) -> i32 { | ---------------- ^^^ expected `i32`, found `()` | | | implicitly returns `()` as its body has no tail or `return` expression ... 87 | res; | - help: remove this semicolon to return this value
所有权只读
1 2 3 4 5 6 7 8
70 | let max_num = dp_max[i-1] + *num; | ------- | | | first assignment to `max_num` | help: consider making this binding mutable: `mut max_num` ... 84 | max_num = Solution::max_abs(dp_max[i],dp_min[i]); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ cannot assign twice to immutable variable
//f(n) 绝对值最大 = n 的 最大值和最小值的绝对值取大 // f(n) 最大值 = f(n-1) 的最大值+n 和 n 取大 // f(n) 最小值 = f(n-1) 的最小值+n 和 n 取小
impl Solution { pub fn max_absolute_sum(nums: Vec<i32>) -> i32 { let n = nums.len(); let mut res = 0;
let mut dp_max = 0; let mut dp_min = 0; for i in0..n { if i == 0 { dp_max = nums[0]; dp_min = nums[0]; res = dp_max.abs().max(dp_min.abs()); }else{ let max_num = dp_max + nums[i]; dp_max = max_num.max(nums[i]);
let min_num = dp_min + nums[i]; dp_min = min_num.min(nums[i]); res = res.max(dp_max.abs().max(dp_min.abs()));
// 定义一个数组 letarr = [1, 2, 3, 4]; // 定义一个向量 letmut vec = vec![1, 2, 3, 4]; // 访问数组的元素 println!("The first element of array is {}", arr[0]); // 访问向量的元素 println!("The first element of vector is {}", vec[0]); // 向向量中添加元素 vec.push(5); // 计算数组的长度 println!("The length of array is {}", arr.len()); // 计算向量的长度 println!("The length of vector is {}", vec.len());