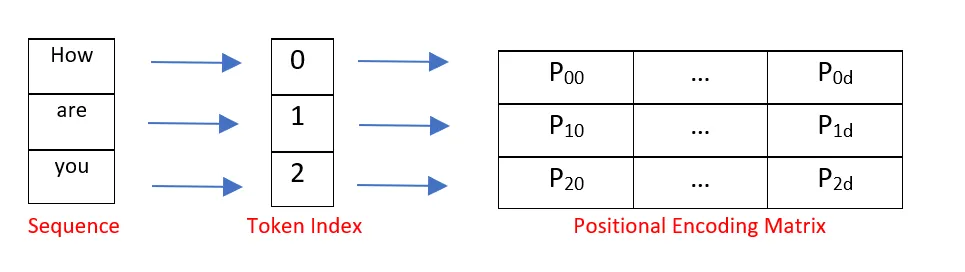
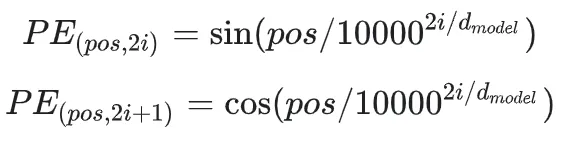def getPositionEncoding(seq_len,dim,n = 10000): PE = np.zeros((seq_len, dim)) for pos in range(seq_len): for i in range(int(dim/2)): PE[pos,2*i] = np.sin(get_angles(pos,i,dim,n)) PE[pos,2*i+1] = np.cos(get_angles(pos,i,dim,n)) return PE
// 定义一个数组 letarr = [1, 2, 3, 4]; // 定义一个向量 letmut vec = vec![1, 2, 3, 4]; // 访问数组的元素 println!("The first element of array is {}", arr[0]); // 访问向量的元素 println!("The first element of vector is {}", vec[0]); // 向向量中添加元素 vec.push(5); // 计算数组的长度 println!("The length of array is {}", arr.len()); // 计算向量的长度 println!("The length of vector is {}", vec.len());
var b58Alphabet = []byte("123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz")
func Base58Encode(input []byte) []byte { var result []byte
x := big.NewInt(0).SetBytes(input)
base := big.NewInt(int64(len(b58Alphabet))) zero := big.NewInt(0) mod := &big.Int{}
for x.Cmp(zero) != 0 { x.DivMod(x, base, mod) result = append(result, b58Alphabet[mod.Int64()]) }
ReverseBytes(result)
for _, b := range input { if b == 0x00 { result = append([]byte{b58Alphabet[0]}, result...) } else { break } } return result
}
func Base58Decode(input []byte) []byte { result := big.NewInt(0) zeroBytes := 0 for _, b := range input { if b != b58Alphabet[0] { break } zeroBytes++ } payload := input[zeroBytes:] for _, b := range payload { charIndex := bytes.IndexByte(b58Alphabet, b) result.Mul(result, big.NewInt(int64(len(b58Alphabet)))) result.Add(result, big.NewInt(int64(charIndex))) }