local get_var = require("resty.ngxvar").fetch local get_request = require("resty.ngxvar").request
request 是 local get_request = require("resty.core.base").get_request
看看 fetch 的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
function_M.fetch(name, request) -- 从 vars 获取值,var 实现了 ffi 获取 uri host remote_addr request_time scheme upstream_response_time 等 local method = vars[name] -- 未实现的直接从 ngx_var 取值 ifnot var_patched ornot method then if num_type[name] then returntonumber(ngx_var[name]) elseif ups_num_type[name] then return sum_upstream_num(ngx_var[name]) end
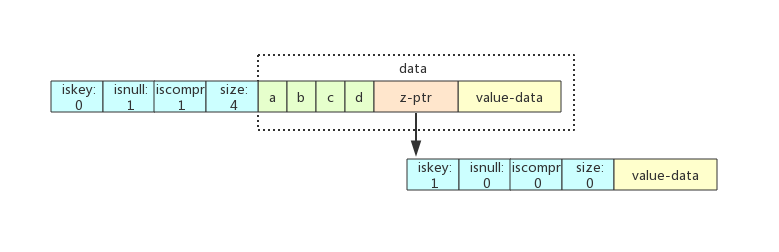
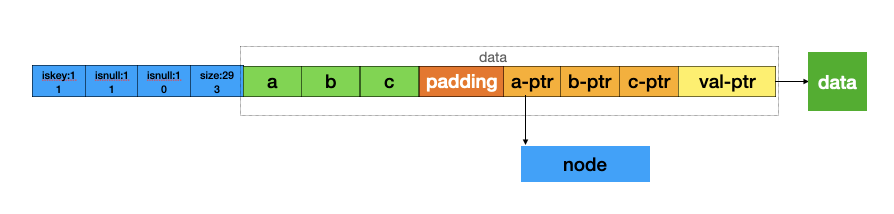
typedef struct raxNode { uint32_t iskey:1; /* Does this node contain a key? */ uint32_t isnull:1; /* Associated value is NULL (don't store it). */ uint32_t iscompr:1; /* Node is compressed. */ uint32_t size:29; /* Number of children, or compressed string len. */ unsigned char data[]; } raxNode;
// 用来查询字符串在redixtree 中能够匹配到哪个位置 static inline size_t raxLowWalk(rax *rax, unsigned char *s, size_t len, raxNode **stopnode, raxNode ***plink, int *splitpos, raxStack *ts) { raxNode *h = rax->head; raxNode **parentlink = &rax->head; size_t i = 0; /* Position in the string. */ size_t j = 0; /* Position in the node children (or bytes if compressed).*/ while(h->size && i < len) { debugnode("Lookup current node",h); unsigned char *v = h->data; if (h->iscompr) { for (j = 0; j < h->size && i < len; j++, i++) { if (v[j] != s[i]) break; } if (j != h->size) break; } else { /* Even when h->size is large, linear scan provides good * performances compared to other approaches that are in theory * more sounding, like performing a binary search. */ for (j = 0; j < h->size; j++) { if (v[j] == s[i]) break; } if (j == h->size) break; i++; } if (ts) raxStackPush(ts,h); /* Save stack of parent nodes. */ raxNode **children = raxNodeFirstChildPtr(h); if (h->iscompr) j = 0; /* Compressed node only child is at index 0. */ memcpy(&h,children+j,sizeof(h)); parentlink = children+j; j = 0; /* If the new node is compressed and we donot iterate again (since i == l) set the split position to 0 to signal this node represents the searched key. */ } debugnode("Lookup stop node is",h); if (stopnode) *stopnode = h; if (plink) *plink = parentlink; if (splitpos && h->iscompr) *splitpos = j; return i; }
local functioncommon_phase(phase_name) local api_ctx = ngx.ctx.api_ctx if not api_ctx then return end -- 执行公共变量 plugin.run_global_rules(api_ctx, api_ctx.global_rules, phase_name)
if api_ctx.script_obj then -- 执行有向无环图编辑的脚本 script.run(phase_name, api_ctx) return api_ctx, true end
return plugin.run_plugin(phase_name, nil, api_ctx) -- 执行插件列表 end
if route.value.plugin_config_id then ... route = plugin_config.merge(route, conf) end if route.value.service_id then ... route = plugin.merge_service_route(service, route) ... end if api_ctx.consumer then ... route, changed = plugin.merge_consumer_route( route, api_ctx.consumer, api_ctx ) ... end
route_items[idx] = { paths = sni, -- 反向后的域名 handler = function(api_ctx)-- 回调函数 ifnot api_ctx then return end api_ctx.matched_ssl = ssl api_ctx.matched_sni = sni end }
证书有两种,全匹配证书,泛域名证书。
1 2 3 4 5 6
for _, msni inipairs(api_ctx.matched_sni) do -- 完全匹配 或者 相对于msni sni_srv 后面没有点(泛匹配)? if sni_rev == msni ornot str_find(sni_rev, ".", #msni) then matched = true end end
local discovery_type = local_conf.discovery for discovery_name, _ in pairs(discovery_type) do discovery[discovery_name].init_worker() end
我们可以在 discovery 目录找到对应的服务发现的实现。服务发现需要实现两个接口。
1 2 3 4
local _M = {} function _M.nodes(service_name) function _M.init_worker() return _M
为了看分析比较简单,可以查看 discovery/dns.lua 的实现。
init_woker 函数初始化了 dns_client 。
nodes 函数通过 dns 服务发现来获取 service_name 对应的服务。并将返回的内容转换成 apisix 的的格式。
1 2 3 4 5
nodes[i] = {host = r.address, weight = r.weight or1, port = r.port or port} if r.priority then -- for SRV record, nodes with lower priority are chosen first nodes[i].priority = -r.priority end